

My editor’s note on yesterday’s version of the When The Going Gets Weird newsletter (which is here or at newsletter.mathewingram.com) got so long, and triggered so many conversations on Mastodon and elsewhere that I thought I would create a separate post about it for anyone who is interested. If debates about the technical and/or ethical challenges involved in getting around paywalls doesn’t interest you, please feel free to move on 🙂
Update: I got into a private debate about this with a prominent author and journalist on Mastodon, and I’ve included some of that below
In a nutshell, I’ve been including workarounds for paywalled articles for a little while now in the newsletter. When I first started it, I just included links and if there was a paywall then I figured people would either ignore it, or try an incognito browser or use some other workaround of their own. But the more I thought about it, the more that approach seeemed thoughtless and inconsiderate, so I started using two tools to produce links that got through paywalls.
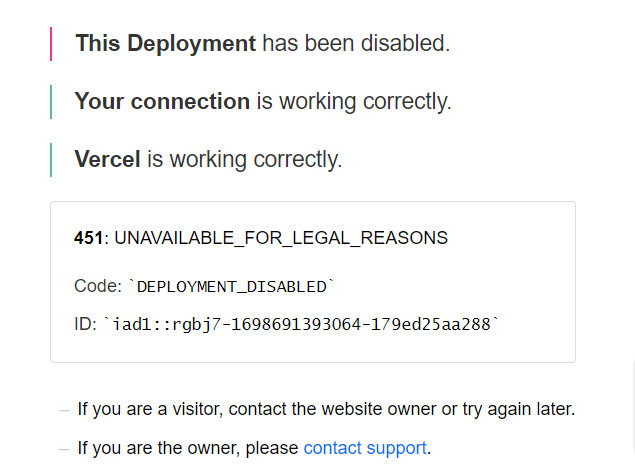
One of them is called 12ft.io, and its motto is (or used to be) “Show me a ten-foot paywall, I’ll show you a 12-foot ladder.” But that tool stopped working for me recently — there’s just an error message from something called Vercel. As it turns out, Vercel is a hosting provider, and they shut off 12ft.io’s access to the site because of an alleged breach of their Terms of Service. I found this out because someone pointed me to a post on Twitter from the founder, Tom Millar, which says that he had no notice of the shutdown.
{kind=link}

The owner of Vercel said 12ft.io caused a lot of work for his service, presumbaly because of complaints from media companies (although Millar says there have only been four requests to take down content). Or, Vercel may have interpreted getting around paywalls as a criminal act, possibly in part because the US Computer Fraud and Abuse Act is a ridiculously vague and punitive piece of legislation that criminalizes all kinds of normal computer usage and white-hat hacking, including discovering content by guessing URLs.
But back to the main event: Another tool I’ve also used is archive.today, which I have not been able to find out much about, despite a lot of digging. Its founder or founders are unknown (to me and Wikipedia at least), and its operation is also somewhat murky. The URL archive,today redirects to one of a number of mirrors, including archive.is, archive.md, archive.ph and others. It’s not strictly speaking a tool designed to get around paywalls — it’s a way of archiving content so that it doesn’t disappear. But it can also be used to get around paywalled content (you can use it yourself to archive things also). If you want to dig deeper into archive.today, start here — thanks to Dwight Silverman for the link.
When I tried to use archive.today, I got a Captcha page that refused to direct me anywhere. I tried it in an incognito window in Chrome, and I tried disabling all of my extensions in case one was conflicting. No dice. It does seem to work in Firefox, for some unknown reason, so I will likely continue to use that (I’ve posted a question about it on the archive.today Tumblr page, which seems to be the only way to reach anyone). And if that doesn’t work, as I explained in my note, I will either post articles that I can gain access to (using this Chrome extension) in a shared public folder at Instapaper, or I will post copies on this site.

As I mentioned in the note, I realize that me helping people get around paywalls may seem hypocritical. Don’t paywalls help support journalism? Perhaps. But many of the sites that have the hardest paywalls are the richest outlets around, like Bloomberg and the Wall Street Journal, so I don’t feel that bad about getting around their hard paywall for a single story. They could make their paywalls more porous, and give readers who come only once in a while a free story, but they choose not to do that. Also, I’ve had a conflicted relationship with paywalls for about a decade or so — I think they should be a last resort, and that membership models like The Guardian’s are a better approach.
To get back to archive.today, it shouldn’t be confused with something called the Internet Archive, about which we know quite a lot compared to the mysterious archive.today. The Internet Archive was founded by Brewster Kahle with some money he made from selling a startup, and his idea was to have a global library that could archive everything on the internet. The Archive and its Wayback Machine has gone some distance towards doing that — including programs, video games, and so on — and Brewster is also involved with an even more ambitious effort called the Interplanetary File System or IPFS.

Archiving things sounds great, but in practice it can become contentious, especially when you are archiving paywalled content and other things that people don’t want you to make a copy of. This became a legal problem for the Archive when they decided to open up their digital book collection during COVID. Previously, they had only offered digital copies of books to one person at a time, in an attempt to duplicate the way that physical libraries work. Pro-copyright forces such as the Author’s Guild didn’t like this much, and they got even more upset when the Archive removed those restrictions during COVID. The lawsuit — which I wrote about here — is ongoing, but the Archive lost the first round because a judge decided lending books is flat out copyright infringement, despite the fact that this works in the physical world.
Anyway, this is all probably a lot more than anyone really wants to know. And it all started because I wanted to include a link in a newsletter, and I couldn’t figure out a way to do it 🙂 Thanks for reading.
Update:
What follows Is a conversation I had with a prominent author and journalist on Mastodon, via private message. I’ve removed anything that I thought might identify this individual, but I thought the points they raised were worthwhile
Author: “Do you have a justification for enabling the theft of copyrighted work? I sometimes write for [publication]. They have a rather tight paywall. I wish they didn’t; I think they’re making the wrong choice. But it’s their choice to make. No one is getting rich there. The writers and editors are entitled to some payment for their work.”
Me: Given the way you phrased your question, I’m not sure my justification will convince you 🙂 But here goes: I don’t think it’s theft to allow someone to read a single article. It isn’t theft in a legal sense (that story can still be sold) or even in an ethical sense. It’s not like I am opening up newspaper boxes and giving everyone copies, or hacking into a server or something of that nature.
Author: “Are you saying you just don’t accept the idea of copyright, and you think copyright violation should not be considered a crime? You don’t believe NY Books has the right to require people to pay before they read articles they publish? Surely you don’t think that it’s okay if it’s just one article but wrong if it’s two, or ten, or a thousand. That can’t be your argument.”
Me: Sorry if I was unclear — in a legal sense, copyright infringement is not theft, although in some cases it is a crime. But there are also exceptions for fair use, as I’m sure you know. Journalistic and research use is often ruled to be fair. In that sense, I do think that a link to one article is not wrong in the same sense that a thousand would be. I expect you will probably see this is a rationalization on my part but that is nonetheless what I believe
Author: “To get around the paywall, people are hosting copies on their own servers. That’s the copyright infringement. Fair use doesn’t enter into it. If you just link to the illicit copy, are you committing a crime? Well no one’s going to come after you. But to me, this is morally wrong. Because I start with the view that the writer does have some right to get paid, and to do that she has the right to control the making of copies. I gather you don’t share that basic view.”
Me: Fair use is a complex concept, but the idea behind it is to allow certain types of use even if they technically involve copyright infringement. In that spirit, I think me providing a link to a paywalled story that is only going to be viewed by a couple of dozen people is arguably fair use. Obviously, you are entitled to disagree! But I don’t think me doing this is going to threaten anyone’s ability to get paid for their work
One Reply to “On getting around media paywalls, archiving content, copyright, and journalistic ethics”